目录
卷积层
神经网络中的卷积是为了模拟视觉皮层细胞的感受野表现出空间局部性
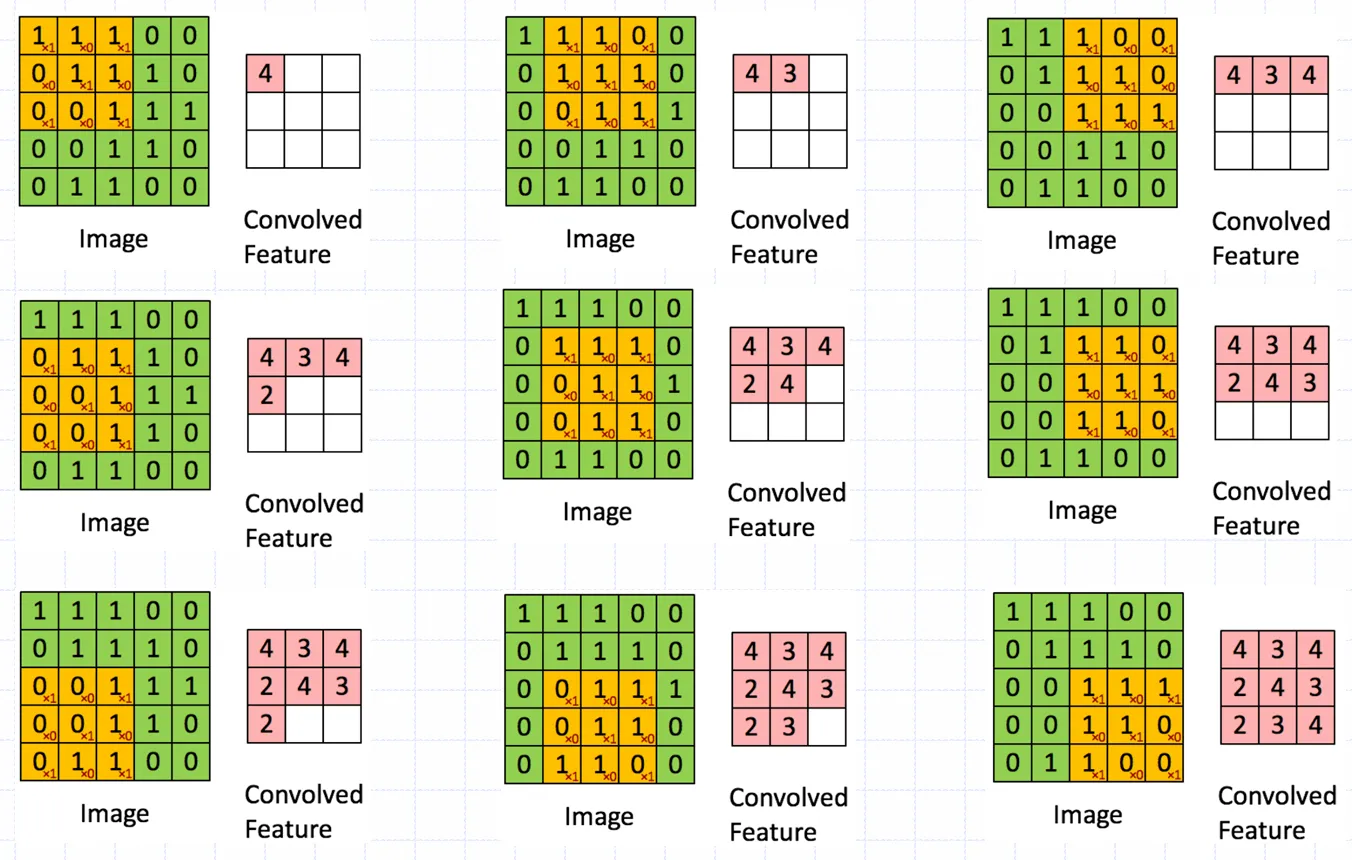
此处的卷积是对上层节点输出的加权和,权值矩阵称为卷积核
池化层
池化将相邻的几个数据合并为一个数据,使得数据的尺寸减小
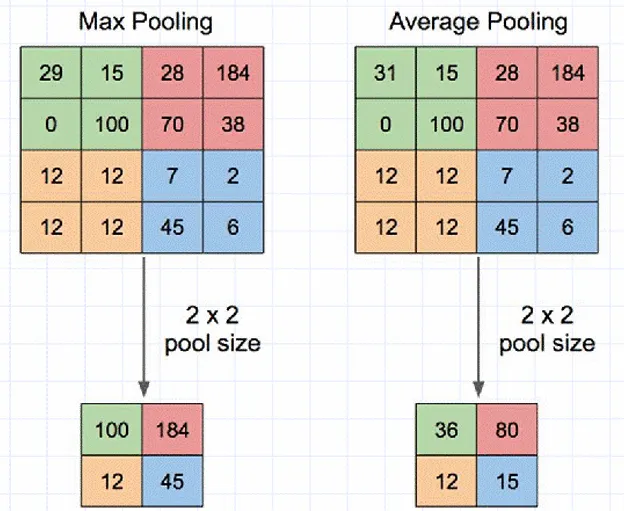
池化能降低卷积层对位置的敏感性;同时降低对空间降采样表示的敏感性;减小了下一层输入大小,进而减小计算量和参数个数;在一定程度上能防止过拟合的发生
池化也称子采样和下采样
多分类神经网络的输出层
在二分类问题中,线性分类器使用Logistic函数
在多分类问题中,输入和输出都需要是一个向量。记输入为
则定义Softmax
Logistic函数就是情形下的Softmax
暂退法(Dropout)
在训练过程中,对于每个神经元以概率保留,以的概率丢弃;丢弃即将其输出固定为0,不参与梯度计算,也不参与权值更新
通过随机丢弃神经元,网络的不同部分在每次训练时都会变得不同,相当于训练多个小规模的子网络。这可以让网络不再过度依赖某些特定的神经元或特征,从而提高网络的泛化性能,使其在新数据上的表现更好
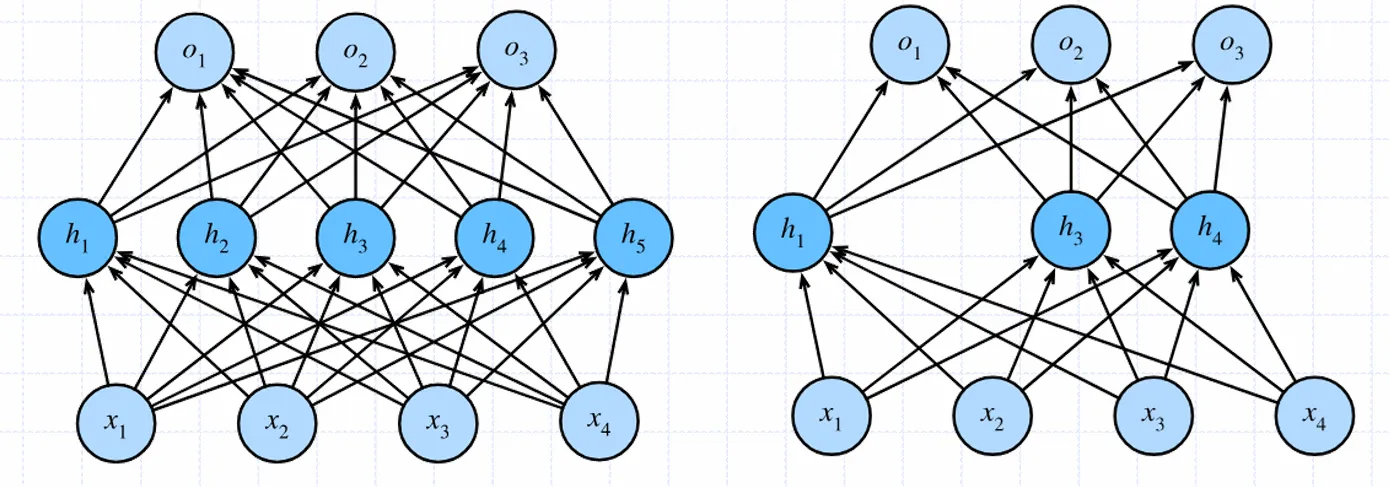
可以把Dropout想象成是在训练过程中让神经网络“强制分工合作”,因为任何一个神经元都可能被忽略,所以网络必须学会让不同的神经元都能贡献一部分任务,从而增强模型的鲁棒性和泛化能力
批量归一化BN
机器学习假设训练数据和测试数据是独立同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的基本保障。不过训练过程中,每一层的参数更新会导致上层的输入数据分布发生变化,层层叠加后,高层的输入分布变化会非常剧烈,给训练带来困难
在训练时,对于每一个小批量样例的前向传播,将神经网络中的某个节点的输出进行重新缩放;假定某个节点在训练中一个批量的数据输出为
那么将其重新缩放为
其中是防止除数为零的较小的常数,是均值是方差,和是可以学习的参数
在前传播中,对一层的节点左批量归一化后再输入给下一层的节点。批量归一化可以带来一系列的性能改善,如加速SGD收敛,防止梯度消失,缓解过拟合等。在某种程度上,批量归一化的效果与残差网络的效果相似
残差网络ResNet
经典的神经网络层间关系为
在残差网络中,从输入直接引入一个短连接到非线形层的输出上,即
用图形象地画出即
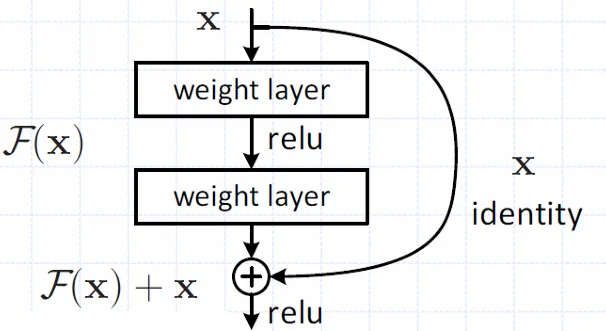
使用残差网络后,能有效缓解高层数网络的梯度消失导致的退化问题(训练集loss增大)
本文作者:GBwater
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!