请注意,本文编写于 578 天前,最后修改于 226 天前,其中某些信息可能已经过时。
目录
神经网络与其前向传播
神经网络的训练与误差反向传播
梯度消失和梯度爆炸
神经网络与其前向传播
一个三层的简单神经网络可以如图画出
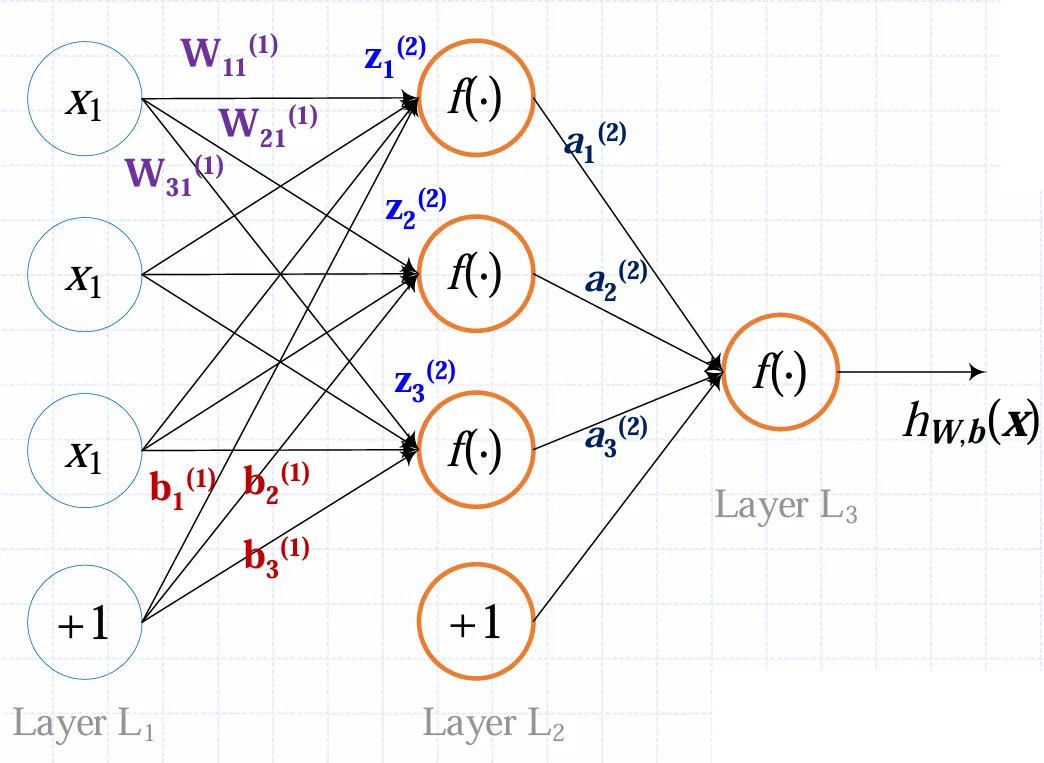
其中xi是输入,+1是偏置,各W是权重,各b是各个神经元的偏置,各z是各个神经元的总输入,各a是各神经元的输出,它们满足
zi(2)=j∑Wijxj+bi(1)
ai(1)=f(zi(1))
写成矢量形式会更加清晰
z(l+1)=W(l)a(l)+b(l)a(l+1)=f(z(l+1))
实际上神经网络可以不止两层,输出神经元也可以不止一个。从输入一层一层地计算得到输出的过程就叫前向传播
神经网络的训练与误差反向传播
神经网络的训练即调整各个权重和偏置,使得代价函数最小。假定有很多个训练样本
(x(1),y(1)),⋯,(x(m),y(m))
对于单个样本定义其代价函数为
J(W,b,x,y)=21∣∣hW,b(x)−y∣∣2
总的代价函数除了各个样本的代价均值外,还要加上权重的惩罚项(Weight decay)
J(W,b)=[m1i=1∑m(21∣∣hw,b(x(i))−y(i)∣∣2)]+2λi,j,l∑∣Wi,j(l)∣2
其中λ是一个超参数,较大的λ会使得训练倾向于减小权值。显然(好像也不显然)J并不是一个凸函数,理论上梯度下降法训练无法达到全局最优;不过实践中发现梯度下降法效果仍然不错
在更新参数时,也应遵循梯度下降法,按照代价函数的梯度更新参数
Wij(l)=Wij(l)−α∂Wij(l)∂J(W,b)
b(l)=b(l)−α∂b(l)∂J(W,b)
鉴于
zi(2)=j∑Wijxj+bi(1)
ai(1)=f(zi(1))
只需要知道每个神经元的z误差即可,定义感知误差,这是一个向量
δ(l)=z(l)∂J(W,b)
利用链式法则可以得到
δ(l)=z(l)∂a(l)⋅∂a(l)∂z(l+1)⋅∂z(l+1)∂J(W,b)=fl′(z(l))(W(l))Tδ(l+1)
即得到了误差的递推关系。那么利用感知误差更新各参数
∂Wij(l)∂J(W,b,x,y)=aj(l)δi(l+1)
∂bi(l)∂J(W,b,x,y)=δi(l+1)
梯度消失和梯度爆炸
神经网络的每一层应当有
an=f(Wan−1)
那么求其导有
∂an−1∂an=f′⋅W
那么当f′<1时,梯度会在传播中越来越小;而W>1时,梯度会越来越大。称之为梯度消失与梯度爆炸
本文作者:GBwater
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA
许可协议。转载请注明出处!